How to be intelligent about artificial intelligence
This was a talk I gave at the third week of the Mostovi Hackathon, to get participants thinking about AI security in development and in production. Read more about Mostovi here — it’s a wonderful initiative by my friend Zhive.
I. Preliminaries
My hope with the contents below is to provide some fruitful context for you all to meditate upon some questions that will be relevant for you.
The moment in AI
A few insights from the State of AI Report 2024 show the magnitude of the current AI moment. Investments are growing, with behemoths like OpenAI and xAI breaking fundraising records, and approaching $100b in total investments into AI companies in 2024:
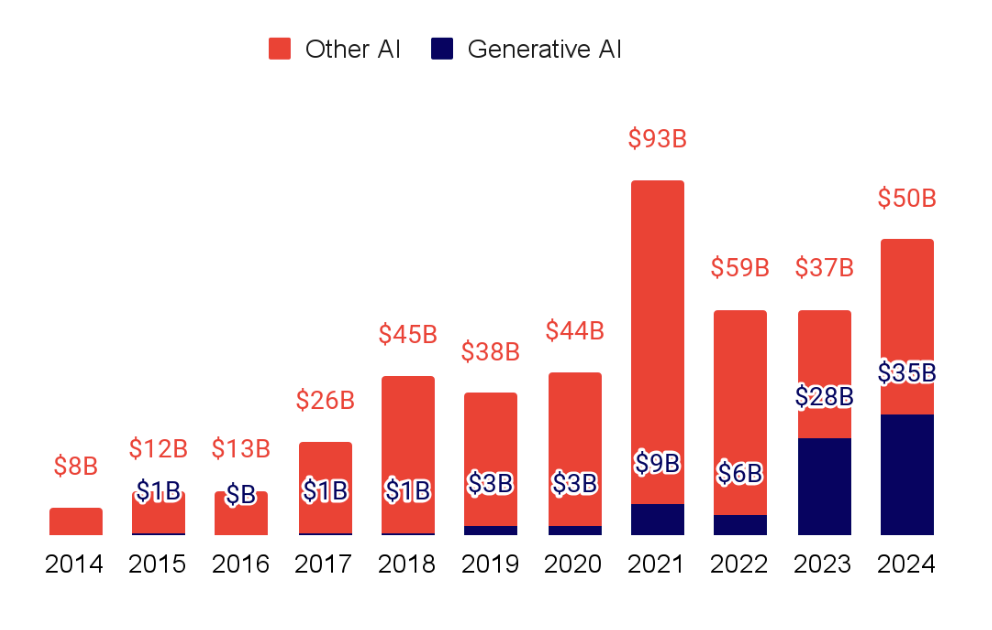 Annual AI investment in generative AI is experiencing a boom (slide 148)
Annual AI investment in generative AI is experiencing a boom (slide 148)
Efficiency gains, algorithmic unhobblings and distilling ever-increasing capabilities into relatively smaller models have yielded dramatic cost reductions:
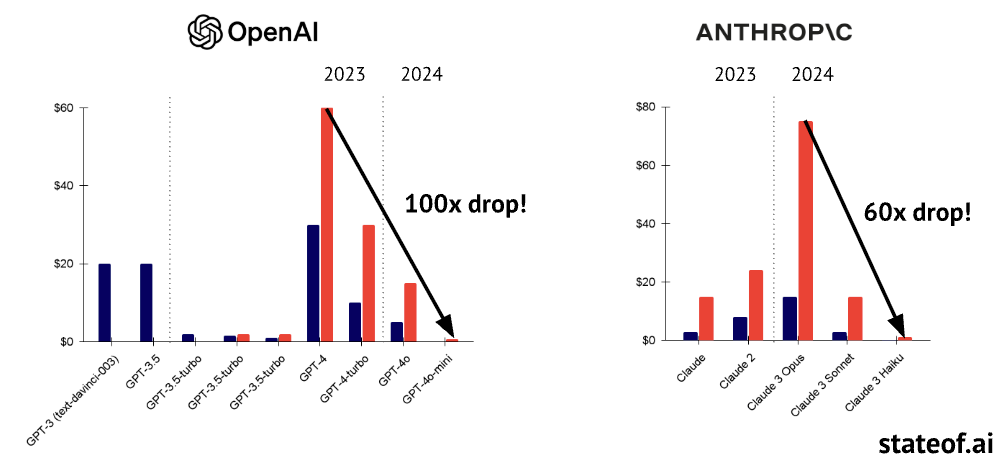 Inference costs of models can drop significantly with distillation (slide 110)
Inference costs of models can drop significantly with distillation (slide 110)
Crucially, despite the waves of “slop” and the economic bubble, users increasingly see value in the latest models:
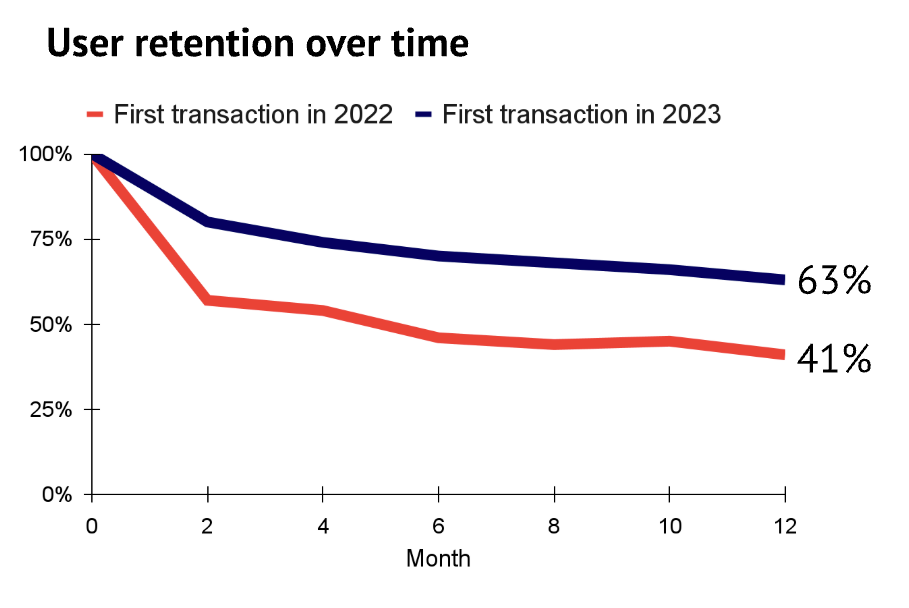 Data from Ramp comparing retention in 2022 and 2023 (slide 133)
Data from Ramp comparing retention in 2022 and 2023 (slide 133)
It is likely that even with existing capabilities, we haven’t even begun grasping the potential applications and there is still a lot of low-hanging fruit. It is certainly dissilusioning to think of failures of models to realize that 9.11 < 9.9, or hallucinations sometimes being more prevalent in reasoners, but mid-2025 is pretty late to be a sour LLM denialist, after systems like AlphaEvolve achieved real breakthroughs in efficient matrix multiplication and LLMs outperform clinicians.
Why care?
You can do great things with LLMs. These tools can yield drastically disparate outcomes — some get smarter using them, and some get dumber. Education studies show this — students learn better when complementing their education with LLMs, but learn worse when substituting their own thinking with LLMs. Google’s CEO has claimed 25% of their codebase is AI-generated, while a quarter of YC startups have entirely AI-generated codebases, showing that LLMs have found their place in helping top-level engineers generate important code. The punchline is: we are responsible for how fruitfully and constructively we use AI. Having a productive time using LLMs is a matter of internalizing a few core principles and following a few best practices.
II. Philosophies and Principles
I have come up with three principles encapsulating a reasonably up-to-date researcher’s view on how to think about these technologies when building (with) them.
II.1. The Bitter lesson
In a 2019 essay, Richard Sutton, one of the pioneers of reinforcement learning — the algorithm used to train the most powerful reasoning models today — coined this term. It makes explicit a realization that AI researchers have been having again and again — that real progress in AI happens not via algorithmic innovations or serendipitous creative breakthroughs, but rather, by scaling computation. Integrating expert human knowledge has mattered little; the innovations that have mattered mattered have been ones making the models amenable to scaling data and compute.
For you, this has an important implication: don’t reinvent the wheel. You should have good reason to forsake strong capabilities available readily via API and instead opt for locally-run smaller models. Basing tool-use agents on a quantized 0.5B Qwen model running on a MacBook Air is going to disappoint you relative to calling GPT-4.1 via API. The same goes for fine-tuning — modern in-context capabilities are strong, and the 80/20 approach is to tune the system prompt, integrate file search tools and/or RAG. Do not fine-tune unless you need to.
Of course, in certain regulatory/budgetary situations, it will make sense to develop custom models and/or fine-tune them on proprietary data. Certain organizations, such as law firms and EU government institutions, are strict about their employees leaking sensitive data to API providers — for this reason, these companies have been implementing in-house solutions or entering into Enterprise plans with providers that are specifically designed to take care of data issues.
II.2. Security mindset
This section is inspired by a blogpost by security technologist Bruce Schneider explaining Professor Tadayoshi Kohno’s Computer Security class at the University of Washington. Professor Kohno has prompted his students to post “security reviews” of common products and services, which you can read here.
An illustrative example in the blogpost:
The poster described how she was able to retrieve her car after service just by giving the attendant her last name. Now any normal car owner would be happy about how easy it was to get her car back, but someone with a security mindset immediately thinks: “Can I really get a car just by knowing the last name of someone whose car is being serviced?”
The largest takeaway that Schneider’s blog and Kohno’s forum teaches us is to have an adversarial mindset. Think of vulnerabilities in your system that a bad actor would love to exploit. Assume data sent over API is not private unless a special agreement has been signed, so anonymize it. Moreover, even well-intentioned collaborations can fail, so be mindful of vendor lock-in — you want to retain flexibility and not get tied up to a single API provider. The AI landscape shifts quickly, so you want to have wiggle room when policies and licenses and priorities change, or when a provider goes bankrupt. All of these examples lead us towards realizing that fallbacks are an instrumental consideration when building with systems as powerful, but as jagged and unpredictable as ML systems in production or during development.
There are three excellent heuristics outlined in a Red Hat blog pertaining to AI security:
Principle of least privilege. Your ML systems, chatbots and LLM assistants should have as little access and control as is absolutely necessary for them to perform their function. Controls should be denied by default, and opted-in. Consider how Claude Code, for example, will require permission before executing system-wide commands unless you explicitly disable this.
Least common mechanism. Containerized environments are popular for a reason. You want to limit the blast radius of a failure by ensuring that other functionalities/users have as little riding on the failed component as possible.
Psychological acceptability. Users will bypass security protocols if they are too cumbersome. In general, it should be easier for your users to exercise the safe behavior than the unsafe behavior.
II.3. Know your stuff
There is no substitute for understanding — it makes you a better engineer and a better entrepreneur.
On an organizational level, it is your responsibility to be aware of the regulations pertaining to your product and the geography of your users. EU AI Act, General Data Protection Regulation (GDPR), California Consumer Privacy Act are not the most exciting bedtime reading, but someone on your team should be rock-solid on what they mean for your users, if applicable.
On a technical level, it’s helpful to think of vibe-coded files and repositories as technical debt that you will have to eventually pay. Just like with real debt, you get immediate liquidity that you will have to compensate with interest, vibe-coding gives you an immediate speedup that will pay its due when you have to implement manual fixes to a 2,000-LOC monster file in 2 months. That’s actually quite a mild case — in a worse scenario, vibe-coding without understanding some security basics can get you quite literally robbed:
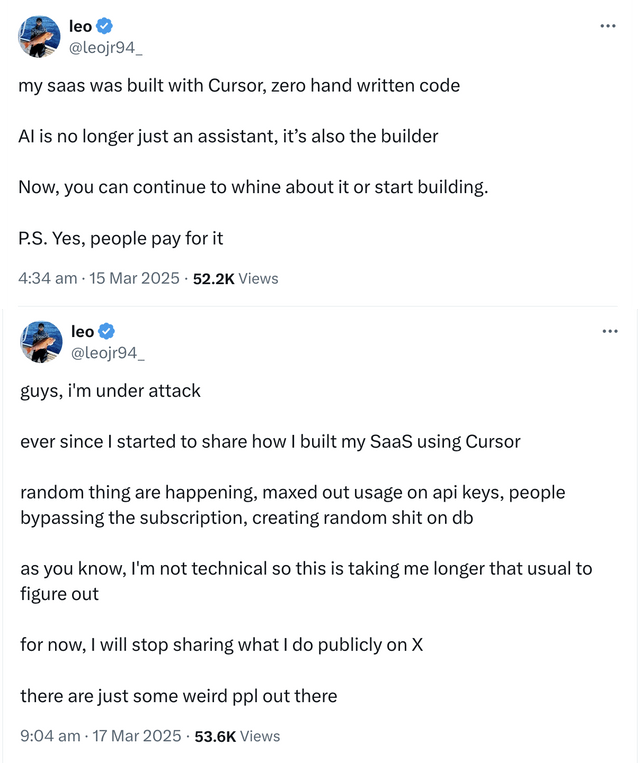 A vibe coder learned the limits of security through vibes (source)
A vibe coder learned the limits of security through vibes (source)
An extra piece of advice for the more curious among you is to go the extra mile. As understanding breeds innovation, it can prove incredibly fruitful to stay up to date with new libraries, GitHub repos showing new methods, and even the limitless supply of ML ArXiv papers.
III. Practical Advice
III.1. Abide to the regulations relevant to you
As these recommendations are aimed at folks building MVPs, I will not talk about things like Data Protection Impact Assessments and Software Development Life Cycle audits. The gist is: be familiar with regulations pertaining to you. For example, for US users, you need a HIPAA Business Associate Agreement with your vendors if you’re gonna handle their health data. Similarly, GDPR is a big consideration if in the EU — your users must know when they are interacting with an AI, or that certain content has been AI-generated. Non-compliance can be costly (millions of EUR).
There are some general considerations you want to be on the safe side of:
-
Use the minimal data you need. Recently, a book by a former Facebook director alleged some unhinged ad-targeting strategies by the social media giant whereby teenagers who had recently deleted selfies were fed ads for beauty products. This is a great example of what to avoid.
-
Bias-test your models and/or data. Check for disparate treatment, discrimination, and leakage of human prejudice into your models.
-
When in doubt, err on the side of asking for user consent. Additionally, allow users to request their data, rectify it, and have it removed if they wish.
This is as far as a non-lawyer as myself will go; I feel far more capable of telling you about the technical considerations below.
III.2. Repository safety
Git is your friend
Version control has been a cornerstone of writing software. It shines even more when you are working with LLM tools that can rapidly make drastic changes to your codebase. Commit your changes incrementally
Here is a great, relatively comprehensive Git cheat sheet by DataCamp, and here is a condensed 2-page version by GitHub.
API key management security
Your API keys should never be hardcoded into your files as strings. Instead, safely store them in an .env file, which is then designated to be ignored by Git in the .gitignore file in your repository.
III.3. Know your AIs
AI capabilities
The landscape is shifting quickly — preferred models for LLM-assisted coding have been changing month-by-month! To have a taste, consider how the programmer’s favorite in the past 12 months — Claude 3.5 Sonnet — was challenged by OpenAI’s o1 (and o1-pro for those able to spare $200 per month) last fall, then by DeepSeek R1 during the January panic, then by Gemini 2.5 Pro’s coding capabilities at long contexts (2 million tokens!) this March, then again in March by o3’s ability to use tools while thinking, before Anthropic again took reclaimed its status with the release of Claude 4 and DeepSeek released a long-anticipated update to their R1 flagship model.
A good way to be aware of what to use during development or in production is to look at benchmarks. Here are favorites of mine:
-
SimpleBench: difficult trick questions that only require high-school level knowledge, but test common-sense and spatiotemporal reasoning. I’ve found it to correlate well with a model’s level of fluid intelligence.
-
LM Arena: an Elo-based leaderboard based on human preference voting. It includes leaderboards per category (like web dev), which is worth paying attention to for LLM-assisted development.
-
ARC-AGI: one of the most important benchmarks, in my opinion. Humans score 100%, and even the best models score below 10%. It measures the degree of fluid intelligence (ability for the models to think on the fly) based on a well-motivated definition of intelligence by Francois Chollet as skill-acquisition efficiency.
-
EQ-Bench: measures the emotional intelligence of models during free-form roleplay. There are categories like creative writing and longform writing, which can further help you decide on models to use if your product requires any of these capabilities.
Besides the test scores, make sure to actually test the models yourself. Benchmarks are an imperfect proxy, and model developers tend to overfit their models to the benchmark at the cost of generalization.
If you’re interested in more Research & Development and AI is a core offering of your startup, stay up to date with ArXiv papers, where the M community is extremely prolific. The AlphaXiv homepage will give you the most popular recent papers, and so will the HuggingFace Daily Papers page. Following the literature closely is an extremely effective way to get overwhelmed, so thread lightly.
Prompt injections
There is a herd of Hagglin’ Harrys who will try to fool your user-facing LLMs and give themselves a 200% discount for whatever you’re selling. If Hagglin’ Harry is in possession of dark prompting skills like certain internet users, you may be in for a rough time if your customer service LLM can make pricing decisions. Exhaustively test the model, and integrate trigger-happy fallbacks to humans when the model is pushed. Classifiers for unsafe prompting can also be integrated so that unusual prompts never even reach the model (although watch for false-positives here).
III.4. Vibe coding
Your stack
Python is the most popular programming language used for machine learning in 2025. Here are some Python libraries that I can recommend:
- uv is a life-changing package manager that you should use instead of
pip;

-
PyTorch is the most popular and comprehensive library for deep learning in Python;
-
Keras might be a preferred option for some, as it provides an intuitive experience that some prefer to PyTorch;
-
Language Model Evaluation Harness: if you want to benchmark models that you perhaps fine-tuned or steered or modified in any way, this library makes it easy to run most of the popular benchmarks easily.
There are many other resources in the wider ecosystem that you can benefit from:
-
HuggingFace is the hub for machine learning developers — not only do they host models, datasets and spaces (demos of ML-powered applications), they maintain popular libraries like datasets and transformers, which are widely used in LLM R&D.
-
OpenRouter provides a single place where you can run inference on LLMs via a unified API, making it easy to manage and switch between models in one place with one credit account.
-
Weights & Biases provides a platform to track and log your ML experiments, which is extremely useful if you are collaborating with others, since saving log files locally and tracking them with git can get overwhelming
-
Prime Intellect, Lambda, Hyperbolic Labs, SF Compute and others provide on-demand GPUs that you can rent (prices are up to a couple of dollars per hour, depending on the GPU) for heavy ML workloads.
Tools for the vibe-coder
The ecosystem for LLM-assisted development provides quite a few options:
-
Cursor, the go-to integrated development environment (IDE) for use with LLMs. It’s extremely well-designed for integrating your repository’s context, and supports both line completions and more agentic capabilities, whereby the LLM can create files and run terminal commands. Alternatives include GitHub Copilot, Windsurf, Replit, v0, Lovable and increasingly more…
-
Terminal tools like Anthropic’s Claude Code and OpenAI’s Codex. They’re both quite competent, as they integrate in your system seamlessly and understand the needed context. These options, however, are pricey — Codex is only available at the most expensive pricing tier ($200/month), whereas Claude Code is estimated to cost around $6 per developer per day on average.
The enthusiastic vibe-coder should pay attention to a few things. Most importantly, caution should be a first-level priority — models can be overconfident, hallucinate and break your working code. Note that virtually every model you use to vibe-code will not be up-to-date with the every latest library — be mindful of the so-called knowledge cut-off. To deal with this, you can give links to documentation pages so the model knows the right implementation. Furthermore, a best practice for a responsible coder is to limit your vibe coding to incremental changes to your codebase that you can easily fix and reverse if need be. Asking Claude to one-shot an entire repository is not a great idea. If you want to do that, you should take more steps to develop a software
A large part of LLM-assisted software development is managing context. LLMs need information about your repository, reference implementations, class/function definitions — be meticulous about giving the model the necessary context for optimal results. Context windows of LLMs — how much text can go in one conversation — are limited, typically to around 100,000 words. Although this can sound like a lot, a solid chunk of that is already taken up by a model’s system instructions, and the model’s “thinking”, which is often extensive, contributes significantly to filling up the context window. Therefore, a best practice is to start new conversations per each new feature you’re implementing, providing the needed context every time. Latency (how long it takes to generate) and quality both suffer at long contexts, so avoid asking for a new edit after 15 conversation turns.
Prompt sensitivity
LLMs are extremely prompt-sensitive by default. It’s worth familiarizing yourself with what kind of prompting seems to work better — this is mostly a matter of trial and error and developers tend to get a sense for it over time. A useful heuristic for prompting reasoning models — which virtually all state-of-the-art coding models currently are — is to give them well-defined, exact goals. The reason this works is the way the models were post-trained, which was through reinforcement learning — when the model writes working code, it gets taught to do that more.
An insightful way to think about prompting reasoning models was shared by Greg Brockman:
 How an o1 prompt should look like (source)
How an o1 prompt should look like (source)
III.5. LLMs in production
The usual recommendations apply — integrate fallbacks everywhere you can, abide by the principle of least privilege (don’t let the model have more control than necessary). On top of that, I would like to highlight two specific considerations that you may find yourself debating.
To fine-tune or not to fine-tune
Bigger models tend to be better — scale is a necessary, but not a sufficient criterion for model quality. The bigger models hosted by API providers often have great general capabilities that allow you to skip fine-tuning. In fact, I recommend only fine-tuning when you know you can devote substantial attention to it and/or if itss your core product. Otherwise, a large API model will be a better choice 9 out of 10 times — you won’t have to worry about GPU costs, inference optimizations, data curation/debiasing and optimal fine-tuning hyperparameters to prevent catastrophic forgetting.
Structured outputs
LLMs are surprisingly good at structured outputs. Turning unstructured text, like a doctor’s report or a bunch of reviews, into structured, analysis-ready data is a task well within the realm where LLMs are comfortable! Some APIs, like OpenAI’s, support a “JSON mode”, where the model returns outputs in JSON mode. This is a situation where you don’t even have to go with the flashy expensive models — using a new small model like GPT-4.1-mini has anecdotally yielded good, stable structured output results in some recent experiments of mine.
One caveat is that structured outputs can harm the performance of reasoning models. Luckily, a new open-source model fresh out of the oven is in for the rescue: Osmosis have trained Osmosis-Structure-0.6B — an ultra-small model to convert a reasoner’s unstructured output into a structured one. That way, you let the reasoner think freely, unencumbered by the output format, and then use a way smaller model to format the response appropriately.
IV. Recap
Thanks for sticking by to the end! The contents above can be boiled down to 2 takeaways:
-
Cultivate trust : limit AI control to the bare minimum, limit the blast radius of failures, integrate fallbacks obsessively, test everything, give users access and control over their data
-
Be situationally-aware : the tools can be excellent scaffolds, and they can also bloat up your repository into an incomprehensible mess. Be meticulous about understanding your core functionality; be bold to experiment, but disciplined to find holes and patch them
Check out Manifold Machines
We are working on a few things:
-
Synglot, a synthetic data & translation toolkit — the goal is to make it easy to bulk translate & generate datasets in low-resource languages like Macedonian;
-
Creating novel, high-quality datasets in Macedonian (released and unreleased), accessible to the wider community for open-source experiments;
-
Training Macedonian reasoners using reinforcement learning — we’re laying the groundwork with the dataset efforts, as well as some training innovations.
Get in touch if you want to get involved!
Enjoy Reading This Article?
Here are some more articles you might like to read next: